
시작하기 앞서.. 본 내용은 CloudNet@ Terraform Study 101 을 진행하며 학습한 내용을 바탕으로 업무에 활용한 내용을 작성했습니다. 따라서 AWS와 terraform에 대한 기본 개념 내용은 생략한 경우가 많습니다. 클라우드 서비스 공급자인 AWS는 고객이 인프라 구성을 간편하게 할 수 있도록 웹 콘솔을 지원하고 있습니다. 이러한 GUI 환경을 좋아하시는 분들도 많이 계시지만, 제 경우, 반복적인 작업 시 휴먼 에러를 방지할 수 있고, 생성하고자 하는 리소스를 한눈에 파악할 수 있기 때문에 콘솔 작업보다 코드 작업을 더 선호하는 편입니다. 처음 AWS를 접하고 VPC, EC2, SG(Security Group), ELB와 같은 기본 서비스를 생성하다보면, 처음엔 어렵지만 손에 익으면..

❄️ Snowflake summit 2023에서 들은 HOL 세션 중, Getting Started with Snowpipe Streaming and Amazon MSK을 진행하면서 작업한 내용을 정리하고자 합니다. Agenda Hands-On Lab: Getting Started with Snowpipe Streaming and Amazon MSK Tue, 6/27, 11:30 AM - 1:30 PM PT James Sun, Partner Sales Engineer, Snowflake Bosco Albuquerque, Partner Solutions Architect, AWS HOL 과정 1. Deploy a managed Kafka Cluster in VPC 2. Use Kafka producer a..
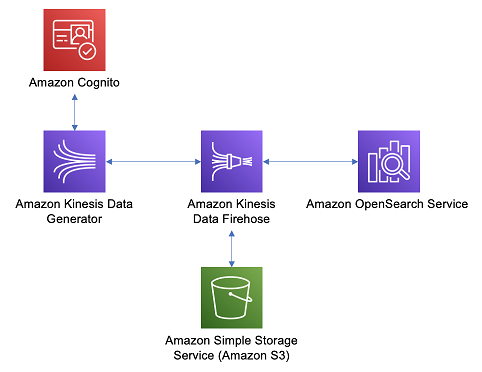
AWS의 Dive into Amazon OpenSearch Service Workshop을 진행하면서 작성한 글입니다. 이번에는 분석을 위해 모든 웹 로그를 수집하는 데이터 파이프라인을 설정해 봅니다. 1. Kinesis Data Firehose 생성 > OpenSearch 에 도메인 연결 > 세분화된 엑세스 제어를 사용해 Firehose가 도메인에 데이터를 씀 2. Kinesis Data Generator에 로그인 > 웹 로그 시뮬레이션 템플릿 지정 > Firehose로 데이터 전송 3. OpenSearch에 이상 감지를 설정해 Generator로 생성한 이상 동작을 감지 4. OpenSearch의 세분화된 엑세스 제어를 설정해 특정 문서 및 인덱스에 대한 차등 엑세스 제공 Data Pipeline 설..
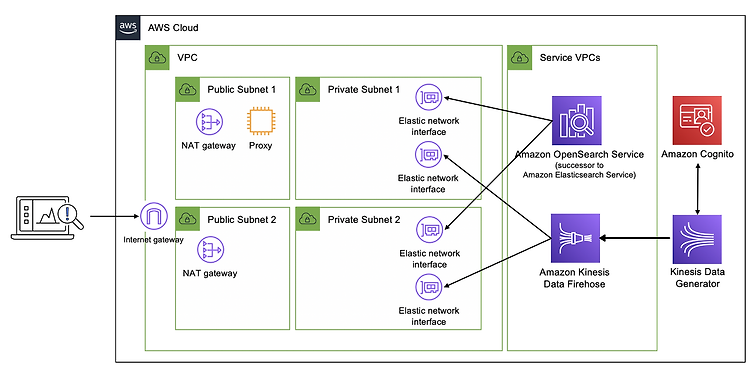
AWS의 Dive into Amazon OpenSearch Service Workshop을 진행하면서 작성한 글입니다. Amazon OpenSearch Service Domain 시작하기 1. Deployment type 워크숍에서는 프로덕션 수준의 확장성과 안정성이 필요하지 않으므로 Dev/test Template, 단일 AZ로 선택합니다. Engine Version : 1.3 2. Data nodes Number of nodes: 2 복제본 샤드(replica shard)를 사용할 것이기 때문에 기본값인 1 대신 2개의 데이터 노드를 사용합니다. 3. Network VPC: (10.0.0.0/16 CIDR 범위가 있는 VPC를 선택합니다.) Subnets: (리스트에 나온 Private 서브넷 중 하..
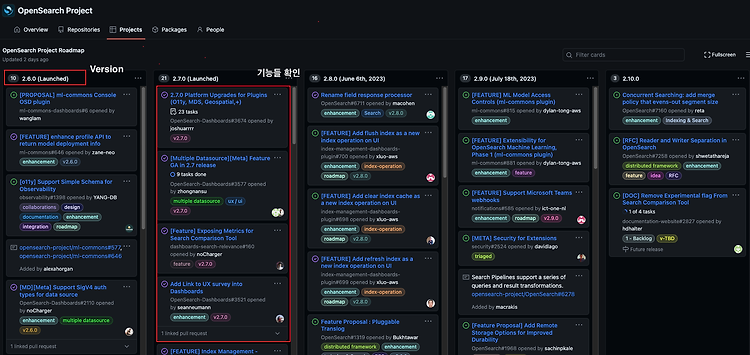
AWS에서 진행하는 Amazon OpenSearch BootCamp for Partners 세션에 참여하면서 공부한 내용들을 정리하려 합니다. 버전별 기능 확인하기 OpenSearch의 경우 기능 추가가 빈번하게 진행되기 때문에 다음과 같은 문서를 확인하면서 기능을 확인할 수 있습니다. 1. GitHub Project 대시보드 확인 OpenSearch Project GitHub 2. AWS 공식 문서 확인 Features by engine version in Amazon OpenSearch Service Amazon OpenSearch Service 기능 3. OpenSearch 공식 Document 확인 OpenSearch Documentation OpenSearch DashBoards 확인 OpenS..
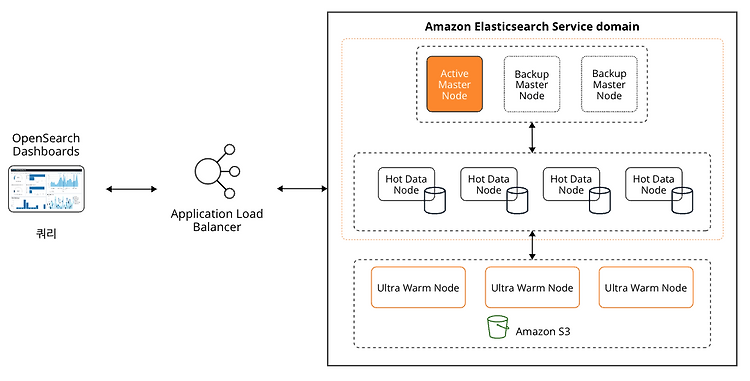
AWS에서 진행하는 Amazon OpenSearch BootCamp for Partners 세션에 참여하면서 공부한 내용들을 정리하려 합니다. 주요 기능 성능 및 확장성 쉬운 사용 보안 및 가용성 1. K-NN(K-Nearest Neighbor) 및 LTR(Learning to Rank) 모델로 검색 품질 및 관련성 향상 2. 사용자 정의 사전, 동의어 파일의 핫리로드(hot-reload)로 즉각적인 검색 정확도 업데이트 1. 세분화된 엑세스 제어 및 감사 로깅으로 모든 수준에서 도메인 보호 2. Trace Analytics를 사용하여 분산 애플리케이션의 성능 및 가용성 문제 해결 1. UltraWarm 및 Cold Storage로 스토리지 비용을 낮추고 데이터 보존 기간 연장 2. 노드 자가 치유(Se..

AWS에서 진행하는 Amazon OpenSearch BootCamp for Partners 세션에 참여하면서 공부한 내용들을 정리하려 합니다. 고객이 직면한 과제 데이터의 폭발적 증가 아래와 같은 다양한 소스에서 굉장히 많은 데이터들이 쏟아져나오고 있습니다. 이런 데이터들이 TB 이상으로 데이터 양이 증가하게 된다면, 사람이 봤을 때 가시적이지 않고, 내가 원하는 정보도 쉽게 찾기 어려워집니다. 애플리케이션과 인프라스트럭처 IT와 데브옵스(DevOps) IoT와 무선 연결 서비스/마이크로 서비스 웹 애플리케이션 비즈니스 애플리케이션 API 데이터베이스 로드 밸런서 네트워킹 서버 오토모티브 홈 디바이스 제조업 모바일 애플리케이션 데이터에서 얻으려는 것 보통 데이터에서 얻고자하는 것들은 아래와 같이 3가지 ..

Snowflake❄️의 Data Warehousing Workshop을 진행하면서 작업한 내용을 정리하고자 합니다. Badge 1: 데이터 웨어하우징 워크샵 - KR 이번 내용은 Lesson 9: Nested Semi-Structured Data 과정을 진행하면서 작성한 내용입니다. 🥋 Load and Query Nested Author & Book JSON Data 🥋 Create a Table & File Format for Nested JSON Data CREATE OR REPLACE TABLE LIBRARY_CARD_CATALOG.PUBLIC.NESTED_INGEST_JSON ( "RAW_NESTED_BOOK" VARIANT ); A JSON file with Authors Nested into ..